はじめに
バックエンドエンジニアとして、コードを書くときやDBオペレーションをする際にレプリケーション遅延に関して注意していることをまとめる。例によってMySQLを前提としている。
MySQLのレプリケーションの仕組み、遅延とは何か
レプリケーションとは、あるインスタンスのデータを別のインスタンスに同期するための仕組みである。構成(トポロジ)の組み方は色々あるが、最も取られるのは書き込みのための「プライマリ」を1台と、読み込み専用の「レプリカ」を複数台用意する構成だと思う。
MySQL8.0のレプリケーションは、各レプリカがクライアントとしてプライマリのサーバーに接続し、バイナリログ(binlog)を通じてほぼリアルタイムに新しい変更を受け取る。
デフォルトでは非同期レプリケーションとなっており、次の流れでデータを同期する。
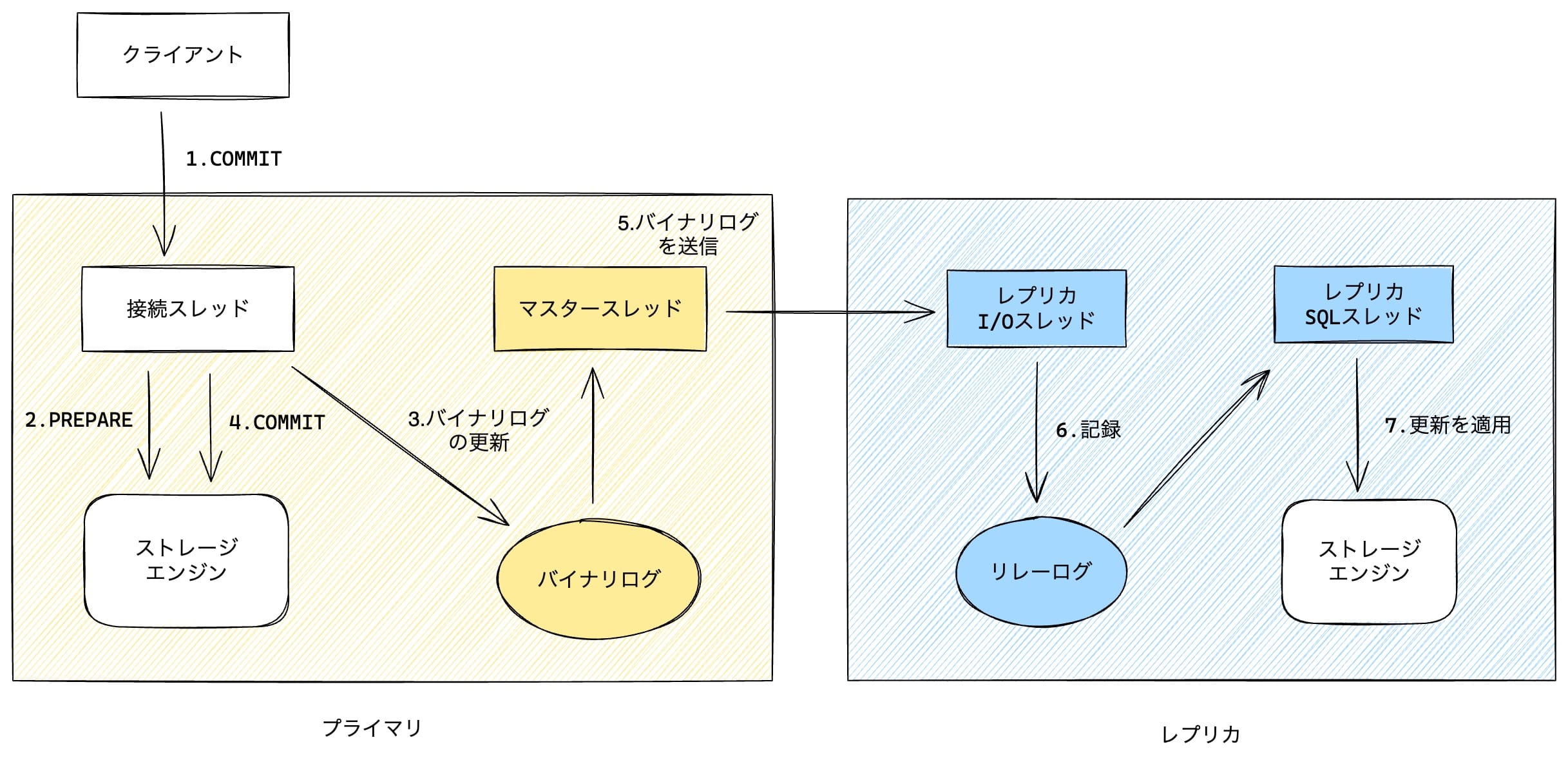
- クライアントはプライマリにCOMMITをリクエストする
- プライマリは変更に対しログを先に更新しトランザクションをPREPARED状態にする。いわゆるWAL(Write Ahead Logging)に従った動きであり、このログをredoログと呼ぶ
- プライマリは変更に対しバイナリログ(binlog)を更新する
- プライマリは変更をCOMMITする
- プライマリから各レプリカへbinlogが送信される
- レプリカは受け取ったbinlogを自らのログに書き込む。これをリレーログと呼ぶ
- レプリカは更新されたリレーログを基に変更を適用する
このように、プライマリは自身のストレージエンジンを更新する前にbinlogを更新するが、それがレプリカに伝搬したことや書き込まれたことまでは確認しない仕組みになっている。
レプリケーション遅延とは、レプリカが6でリレーログに書いた最後の変更のタイムスタンプと、7で実際に適用が完了した最後の変更のタイムスタンプの時間差のことである。これはSHOW SLAVE STATUS で表示される Seconds Behind Master で確認できる。
📝 参考: 準同期レプリケーション
MySQLでは 準同期レプリケーション がプラグインの形でサポートされている。準同期レプリケーションでは、少なくとも1台のレプリカがbinlogを受け取り、リレーログに書き込んだことを待ってから(プライマリでACKを受け取ってから)、プライマリでトランザクションをコミットする。準同期の場合、レプリカへのコピー前にプライマリが落ちた場合にも、少なくとも1台のレプリカにはその変更が伝達されていることが保証されているので、データ整合性が向上する。しかし遅延の完全な対策とはならない。
遅延はいつ起こるのか
細かく見ると色々あるかと思いますが、起きやすいのは
- テーブルにカラムやインデックスを追加するDDL適用時
- カラム値を一斉に変更するような DML適用時
の2つかなと思っている。この場合、重いクエリを投げたことにより、7番のSQLスレッドでの変更適用に時間がかかり遅延が起こる。
アプリケーションへの影響
レプリケーション遅延が起こると、プライマリから書き込んだ変更がレプリカにまだ反映されていない という状況が生じる。よって、アプリケーションへの影響はレプリカをどのように使っているかに依って変わる。
例えばブログサービスで考えると、遅延によって次のようなことが起きるかもしれない。
-
新しい記事を投稿したが、記事一覧に表示されない
→
原因: 記事作成APIは成功しておりプライマリにデータが追加されている。しかし、記事一覧APIはレプリカからデータを取得しているため反映が遅れている
-
記事に対していいねをしても、いいね数が変化しない
→
原因: 記事いいねAPIはプライマリにいいねを作成したが、その後一度、レプリカから最新のいいね数を引き直した上でレスポンスを構築しており、遅延により値が変化しない。
-
記事に対するいいねはユーザーあたり1つまでのはずが、何度もいいねできてしまう
→
原因: 記事とユーザーの間の現在のいいね状態をレプリカから取得しており、いいねレコードを複数作成できてしまう
1のケースは、記事一覧APIでレプリカを使用しているために起こる問題である。しかしそもそも負荷分散等のためにDBの冗長構成を組んでいるわけなので、レプリカからデータを読むことは自体は問題ない。またシステム上も致命的なエラーではないが、シナリオによってはUXに大きな影響がありそうだ 。
次に2のケースは、ユーザーが記事ページを開いてからユーザーがいいねボタンを押すまでに、他のユーザーがいいねを付けている可能性があるので、いいね数の引き直しは必要であるものとする。1のケースと違うのは、APIによってプライマリ/レプリカの使い分けが異なることで起こる問題ではなく、同一API内で一連の処理の途中でレプリカに切り替えてしまうことで起きる問題 であることだ。
最後に3のケースは、記事とユーザー間のいいね状態を持つ中間テーブルのようなものがあったと仮定すると、本来であればレコードは1つしか作成できない制約があるにも関わらず、複数レコード作成されてしまう可能性がある。これは場合によっては、致命的なデータ不整合につながる可能性があり、注意が必要である。
また上記とは全く別の視点として、Debeziumを使ってCDCを構築しているケースなど、直接的にレプリケーションのクライアントとしてbinlogを使って動作するようなアプリケーションを運用している場合は、遅延による影響をダイレクトに受けてしまうだろう。
対策1. 遅延が起きても問題ない作りにしておく
遅延対策の1つは、アプリケーション側をあらかじめ遅延を想定したつくりにしておくことだろう。
例えば先のブログサービスの2のケース
記事に対していいねをしても、いいね数が変化しない
では、リソースを変更した直後の引き直しにプライマリを使うようにすることで対策できる。大事なのは、1つ1つの処理を書く中で、プライマリから取得すべきなのか、レプリカに負荷を流すことが優先なのかを考えることだと思う(当たり前ではありますが)。個人的に特に気をつけていることは、遅延が発生している最中にリソースを作成したり更新した場合でも、データ不整合が発生しないようにすること。よってPOSTやPUT、DELETEのAPIの中でレプリカを使うときは特に注意している。
また3のケースでは、データ不整合が発生しうる前提で例を書いていたが、記事とユーザー間のいいねテーブルに適切な主キーまたはユニーク制約を作ることで、あらかじめデータ不整合が発生しないようにできるはずだ。不整合が起きないようにあらかじめ付けられる制約は付けておくことが大事だと思う(これも当たり前ではありますが…)。ただし、RDBでは複数テーブルをまたぐような制約をかけるのが難しい場合もあるため、アプリケーション側でチェックする時は必ずプライマリを使うと良さそうだ。
対策2. そもそも遅延しないようにする
最後に大事なことを書くのは構成としてあまり良くないが、こちらが根本対策となるだろう。アプリケーション側でいくら工夫しても、遅延が発生してしまえばレプリカを使う限りは必ず影響が出てしまうためだ。
DDL適用時の対策
-
インスタント方式のDDLに変更できないか検討する
MySQLではオンラインDDLがサポートされており、DDLはインスタントかインプレース方式で適用される。 DDLがインプレース方式になる場合には、テーブルサイズに比例して実行時間が長くなってしまうため、まずはインスタント方式で済むDDLに変更できないか検討する。
例を挙げると、カラムの追加はテーブルの最後のカラムとして追加する場合はインスタントにできるが、間に差し込む場合はインプレース方式となりテーブルが再構築される。
過去の経験として、
- 数百万件のテーブルに対するセカンダリインデックスの追加(テーブル再構築なし)は、1分程度で終わった
- 億超えテーブルに対して同じくセカンダリインデックスの追加(ただし上記と違い複合インデックスだった)は3時間ほどかかった
のような例があった。テーブル再構築が必要なDDLはさらに注意が必要だと思う。オンラインDDL の表を必ず事前に参照したい。
参考: 第30回 InnoDBオンラインDDLについて | gihyo.jp
-
RSU (Rolling Schema Upgrade)
インスタントDDLに変えることが難しく、テーブルの再構築が走ってしまう場合に検討する方法である。遅延という概念をそもそも無くす逆転の発想のやり方でとても面白い。次のような手順でDDLを手動で適用する。
- 対象のDDLをbinlogに書かないようにする
- レプリカから先にDDLを適用する
- プライマリにDDLを適用する
この手順により、そもそもDDLに対してレプリケーションが発生しないので遅延を無くすことができるというわけだ。
デメリットとして、DDLをレプリカに先に適用した時にレプリケーションに影響がある場合は使えないことと、DDLに対してはbinlogが出力されない点がある。
-
gh-ost (online-schema-migration-tool)やpt-osc (online-schema-change)を使う最後に、専用のツールをつかってDDLを適用する方法がある。内部的な詳しい方式の説明は詳しくないので割愛するが、これらのツールを使うことで
- MySQLではオンラインで適用できない(並列のDMLが許可されない)DDLもオンラインで適用できる
- レプリケーション遅延やサーバー負荷のしきい値を設定し、それを超えないようにコントロールしながらDDLを適用できる
ようになる。
デメリットとして、内部的にDDL対象のテーブルのデータをバッチでコピーしていくのだが、過去にそこでデッドロック発生した経験がある。どの方法を取るにしてもそうですが、できるだけリクエストが少ないタイミングを狙って実施したほうが良いでしょう。
DML適用時の対策
DMLの場合は、シンプルにバッチを書いて少しずつ行を更新していくことで対策できる。更新を小分けにすることでそもそも遅延が起こらないことが期待できるのと、多少遅延が発生しても、アプリから来たトランザクションと交互に実行されていくので影響を小さくできる。
適切なバッチサイズは一概には言えないが、大体1万件以内にすると安心だと考えている。
さいごに
ここで記載した内容は、必ずしもバックエンドエンジニアが直接作業する領域とは限らないが、WebアプリにとってDBは生命線なので、少なくとも概要としては一通り把握しておきたいと思っている。今後も知見が増えたら加筆していきたい。
また書きながら気になっていることとして、MTS(Multi Thread Slave)/MTA(Multi Thread Applier)と呼ばれる、レプリカ側のSQLスレッドを複数生成しbinlogを並列で再生する機能がある。これはあらゆる変更に対して有効というわけでは無いと思うが、そもそもプライマリで同時DML可能なクエリはレプリカでも同じことをすればレプリケーション遅延せずに済むのではないかと思っているので、詳しく調べてみたい。
第79回 MySQLのマルチスレッドスレーブ | gihyo.jp
