はじめに
deleted_atにインデックスを雑に貼ったら本番DBが死んだ という記事で
IS NULLが大多数を占めるカラムに単独インデックスを貼ってはいけません。
と述べられていたのですが、なぜ特別 NULL に気をつける必要があるのか、よくわかりませんでした。
またそもそも、オプティマイザがどのようにインデックスを選択しているのか知らなかったので、今回は重要な指標である平均グループサイズについて整理してみます。
選択性の期待値 ─ 平均グループサイズ
オプティマイザは、テーブルやインデックスの統計情報を基に実行計画を決める。中でもインデックス選択で重要なのが、テーブルから読み込むであろう行数の見積もり(rows)である。これは小さいほど良い。
rowsはEXPLAIN コマンドで確認できる。ここに表示されるのはkey として選んだインデックスを使った場合の値である。豆知識として、クエリに FORCE INDEX を追加すれば、特定のインデックスを選択した場合の値も確認できる。
+----+-------------+--------+--------+---------------+------+---------+--------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+--------+---------------+------+---------+--------+------+----------+-------------+
| 1 | SIMPLE | sample | ref | key1,key2 | key1 | 6 | const | 1 | 100.00 | Using where |
+----+-------------+--------+--------+---------------+------+---------+--------+------+----------+-------------+オプティマイザが rows をどのように推定するのかはクエリパターンによって様々だと思われるが、今回は理解しやすいように単純な等価検索(例: col = ?)について考えると、平均グループサイズが推定の土台となる。平均グループサイズは「同じインデックス値を持つ行が平均して何件あるか」を意味している。
平均グループサイズ = テーブルの行数 (n_rows) / そのインデックスのカーディナリティ (n_diff)もしインデックスが単一カラムインデックスならば、カーディナリティはそのカラム自体のカーディナリティと等しい。
例えば従業員のテーブルがあったとき、1万人の従業員がいて部署名 のユニーク数が50とすれば、1部署あたりの人数は平均200人になる。つまり、部署名 = ? という条件で検索した場合、オプティマイザは「この条件に一致する行はだいたい200件くらいありそうだ」と見積もることができる。
もし 部署名 と 名前 のそれぞれの単独インデックスが使える場合、 名前 の方がより絞り込めそうだなと判断できる。
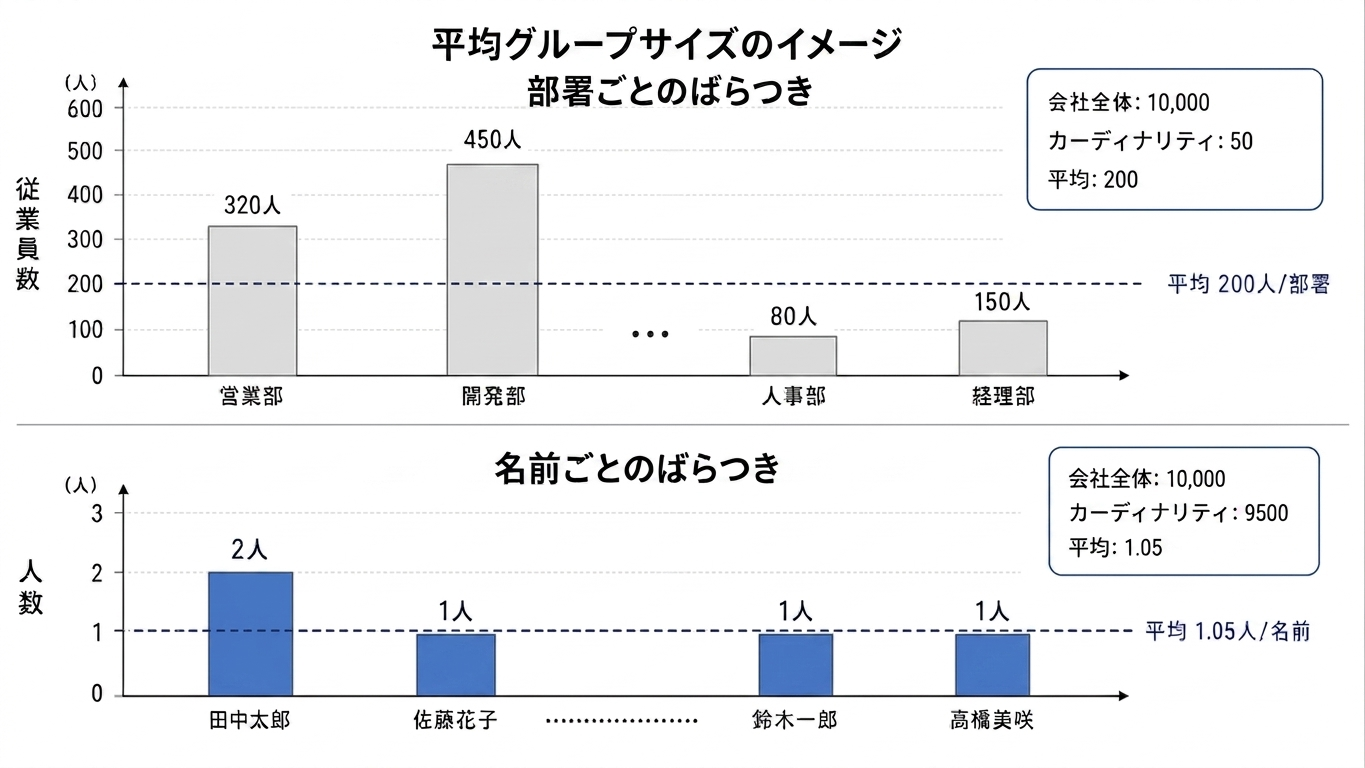
MySQLでは基本的に、1テーブルにつき1インデックスしか使用できないため、複数のインデックスが利用できる状況では、rows が小さい方が選択されやすい。
📝 複合インデックスのカーディナリティ
- 左から1列使う:
n_rows / Card(c1) - 左から2列使う:
n_rows / Card(c1, c2) - 左から3列使う:
n_rows / Card(c1, c2, c3)
ここで、Card(c1, ..., cN) は (c1, ..., cN) の組のユニーク数である。
グルーピング時のNULLの取り扱い
innodb_stats_method というシステム変数があり、InnoDB の場合に NULL をどうグルーピングするか設定できる。とれる値は次の3つ。
nulls_equal:NULLをすべて同じ値として扱う(単一の値グループとなる)nulls_unequal:NULLをそれぞれ異なる値として扱うnulls_ignored:NULLを統計計算から除外する
デフォルトで nulls_equal となっており、すなわちこれはNULL も1つの値として扱うということである。
nulls_unequal や nulls_ignored を使ってしまうと、データが NULL に偏在するケースで rows が過小評価されることになる。
平均グループサイズの確認方法
先に書いたように、平均グループサイズは次のように求める。
平均グループサイズ = テーブルの行数 (n_rows) / そのインデックスのカーディナリティ (n_diff)では、実際にその値はどこで確認できるのか。InnoDBの場合、mysql.innodb_table_stats と mysql.innodb_index_stats からわかる。
まず、テーブルの行数は mysql.innodb_table_stats の n_rows を参照する。
SELECT
table_name,
n_rows
FROM mysql.innodb_table_stats
WHERE table_name = 'tickets';+------------+--------+
| table_name | n_rows |
+------------+--------+
| tickets | 999657 |
+------------+--------+次に、カーディナリティは mysql.innodb_index_stats テーブルを参照する。このテーブルにはいくつか統計情報が含まれているが、stat_name がn_diff_pfx... の行を見る。
SELECT
index_name,
stat_name,
stat_value,
stat_description
FROM mysql.innodb_index_stats
WHERE table_name = 'tickets'
AND stat_name LIKE 'n_diff_pfx%'
ORDER BY index_name, stat_name;+---------------------------------------+--------------+------------+------------------------------------+
| index_name | stat_name | stat_value | stat_description |
+---------------------------------------+--------------+------------+------------------------------------+
| PRIMARY | n_diff_pfx01 | 999657 | id |
| idx_tickets_assignee_deleted_priority | n_diff_pfx01 | 1693 | assignee_id |
| idx_tickets_assignee_deleted_priority | n_diff_pfx02 | 513677 | assignee_id,deleted_at |
| idx_tickets_assignee_deleted_priority | n_diff_pfx03 | 537047 | assignee_id,deleted_at,priority |
| idx_tickets_assignee_deleted_priority | n_diff_pfx04 | 1063548 | assignee_id,deleted_at,priority,id |
+---------------------------------------+--------------+------------+------------------------------------+例えば、tickets テーブルに idx_tickets_assignee_deleted_priority(assignee_id, deleted_at, priority) なる複合インデックスがあるとする。
この場合、次のように対応する。
n_diff_pfx01:assignee_idのユニーク数n_diff_pfx02:(assignee_id, deleted_at)の組のユニーク数n_diff_pfx03:(assignee_id, deleted_at, priority)の組のユニーク数
pfx は prefix の意味であり、インデックスの左から何列分を見るかを表している。MySQLのインデックスは暗黙的に主キーを含むため、pfx04 は (assignee_id, deleted_at, priority, PK) となる。
平均グループサイズを求めるときは、innodb_table_stats.n_rows を、条件に対応する innodb_index_stats.stat_value で割ればよい。
SELECT
i.index_name,
i.stat_name,
i.stat_description,
t.n_rows,
i.stat_value AS n_diff,
ROUND(t.n_rows / i.stat_value, 2) AS avg_group_size
FROM mysql.innodb_table_stats t
INNER JOIN mysql.innodb_index_stats i
ON t.database_name = i.database_name
AND t.table_name = i.table_name
WHERE t.table_name = 'tickets'
AND i.index_name = 'idx_tickets_assignee_deleted_priority'
AND i.stat_name LIKE 'n_diff_pfx%'
ORDER BY i.stat_name;+---------------------------------------+--------------+--------+---------+----------------+
| index_name | stat_name | n_rows | n_diff | avg_group_size |
+---------------------------------------+--------------+--------+---------+----------------+
| idx_tickets_assignee_deleted_priority | n_diff_pfx01 | 999657 | 1693 | 590.46 |
| idx_tickets_assignee_deleted_priority | n_diff_pfx02 | 999657 | 513677 | 1.95 |
| idx_tickets_assignee_deleted_priority | n_diff_pfx03 | 999657 | 537047 | 1.86 |
| idx_tickets_assignee_deleted_priority | n_diff_pfx04 | 999657 | 1063548 | 0.94 |
+---------------------------------------+--------------+--------+---------+----------------+注意点として、これらの値はあくまで推定値であり、実際の行数を正確に数えたものではない。オプティマイザは概算値から実行計画を判断する。
平均グループサイズの弱点
年収について語る時に平均値を使うと一部の高所得者に引っ張られて実態を見誤るように、平均グループサイズもデータ分布が偏っている場合は実際のアクセス行数と大きく乖離することがある。
これに関しては deleted_at がとても良い例である。多くのレコードが未削除であるので、データは NULL に偏在しがちである。他方、レコードが削除されるタイミングは分散しやすいので、カーディナリティは大きくなる。平均グループサイズが同じでも、一様分布と歪みのある分布では実際にアクセスする行数が変わることに注意が必要である。
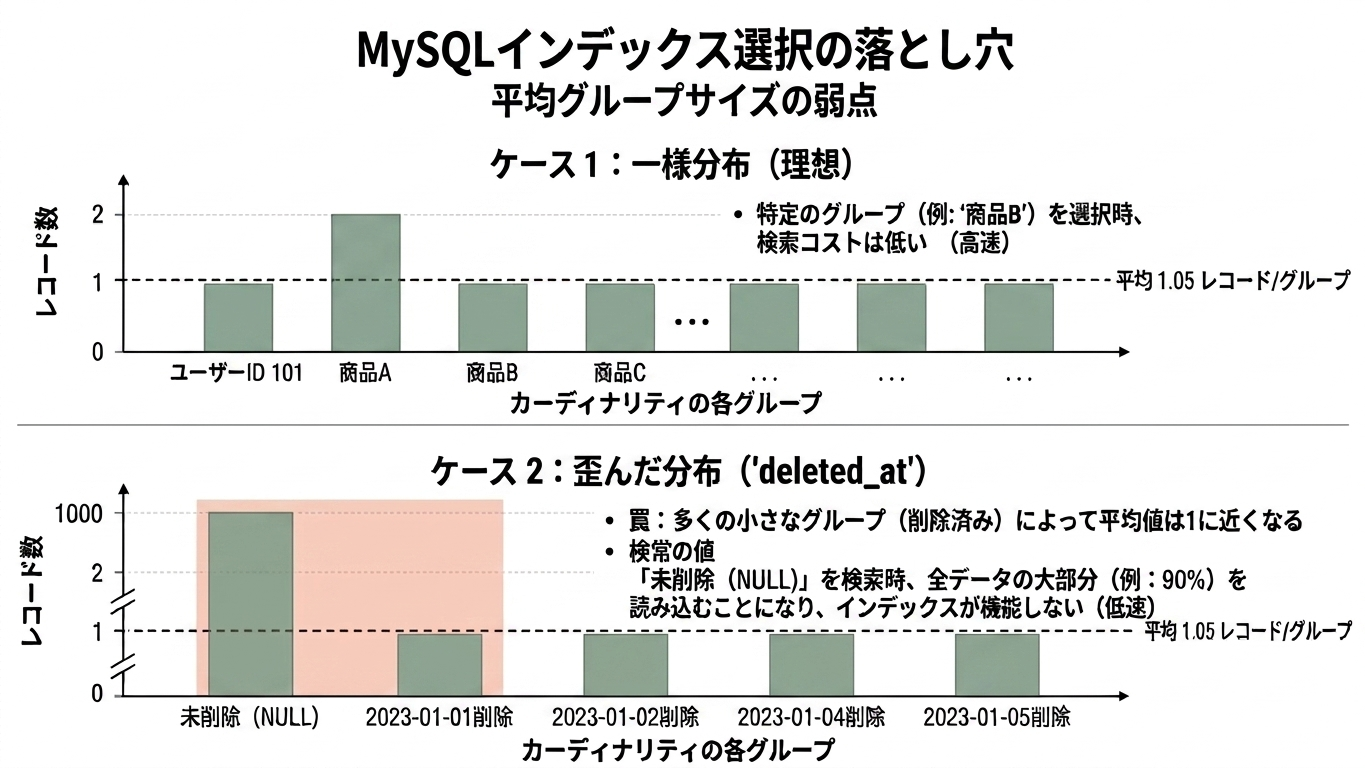
統計情報の誤差
deleted_atにインデックスを雑に貼ったら本番DBが死んだ の再現環境を作っていてわかったのだが、統計情報がサンプリングベースで推定されていることで誤差が想像よりも大きい場合がある。またそれにより、理論的には起き得ない逆転現象すら発生しうることがわかった。
例えば、これまでの説明に基づけば、次のようなことが言える。tickets というテーブルに
idx_tickets_deleted_at (deleted_at)idx_tickets_assignee_deleted_priority (assignee_id, deleted_at, ...)(左2列までを使う)
のような2つのインデックスがあったとする。これらのカーディナリティは常に 1の単独インデックス <= 2の複合インデックス となるはずです。なぜなら、両方のインデックスに deleted_at が含まれており、複合インデックスはさらに assignee_id とのかけ合わせとなるため。
ところが、tickets テーブルのデータを色々と変えていると、平均グループサイズが逆転する現象が起こった。
+---------------------------------------+--------------+--------+---------+----------------+
| index_name | stat_name | n_rows | n_diff | avg_group_size |
+---------------------------------------+--------------+--------+---------+----------------+
| idx_tickets_assignee_deleted_priority | n_diff_pfx02 | 999657 | 513677 | 1.95 |
| idx_tickets_deleted_at | n_diff_pfx01 | 999657 | 640908 | 1.56 |
+---------------------------------------+--------------+--------+---------+----------------+この状態で assigee_id で結合が必要な users テーブルとのJOINを行いidx_tickets_deleted_at を選択すれば、rows の推定が1.56行であるにも関わらず、実際には論理削除されていない数十万件にアクセスすることとなり、フルスキャンに近い状態となります。これは厳しい。
...
-> Filter: ((tickets.assignee_id = users.id) and (tickets.deleted_at is null)) (cost=0.39 rows=1.56)
-> Index lookup on tickets using idx_tickets_deleted_at (deleted_at=NULL) (cost=0.39 rows=1.56)また元記事によれば、assignee_id はJIRAのようなチケットの担当者を示すカラムであるため、本番環境のDBでは未削除レコード(deleted_at IS NULL)のほとんどが異なるユーザーに紐づいていると予想されます。となれば、複合インデックスのカーディナリティは単独インデックスよりも実際には相当大きいはずです。にも関わらず誤って単独インデックスが選ばれたとすると、統計情報の推定誤差が思ったよりもデカかったのではないかと考えられる。
まとめ
オプティマイザについて調べていると芋づる式に新しいことがわかり、やや発散気味になってしまった。
インデックス選択において、平均グループサイズが重要である。ただし平均値であるため、データ分布が偏っていると特定の検索では不適切な実行計画になる場合がある。例として、論理削除で使いがちな deleted_at のようなカラムでは、 NULL にデータが偏在しかつカーディナリティが高くなりやすいため、平均グループサイズが過小評価されやすい。
元記事では nulls_equal による統計の歪みが原因として挙げられていたが、より正確には平均グループサイズの特性の問題である。nulls_equal の設定自体はむしろ適切であり、nulls_unequal や nulls_ignored に変えると平均グループサイズを過小評価するリスクがある。
加えて、統計情報は概算値であり誤差が大きくなるケースがありそうだ。実行計画の選択ミスは思ったよりも簡単に、不合理的に発生する可能性がある。このあたりは、元記事にもコメントさせていただいた。
対策として、値が偏在するカラムへの単独インデックスの作成には注意を払いたい。とはいえ、オプティマイザが実行時にどう判断するかを完全に予測することは難しいので、個人的にはインデックスヒントを積極的に活用するのは1つの手だと思う。最後に、むやみにインデックスを貼らないこと。INSERTのオーバーヘッド、ストレージ容量が無駄に増え、既存のクエリを壊すリスクさえ孕む。
分布が偏るケースについて、じゃあヒストグラムを統計情報として持ったら良いのにと思うが、どうやらそのような機能もあるらしい。どれくらい使われているのか不明だが深掘りすると面白そう。また統計情報のサンプリングに関する設定もあるので、そのあたりのパラメータを調整して rows 推定の精度を高める手もありそうだ。