はじめに
データベースまわりで何か試すときに データをシュッと用意できると嬉しい。
もっと言うと、docker composeでMySQLを動かそうとすると必ずどこかでハマる(自分だけかな、だいたい接続で詰まる)ので、動くまでの環境構築をシュッとできると嬉しい。
ということで、公式のドキュメントに載っているサンプルデータ が入った状態のMySQL serverをdocker composeですぐに起動できるコードを用意した。
データ毎にコンテナを起動するようになっていて、userとpassは共に’test’で入れるようにしてある。1つのコンテナに全データを収録しても良かったが、あまり深く考えていなかったのと、データの入れ直しやすいので良いことにしよう…。
現在対応しているのは次の3つのデータのみ。
ここからは各データがどういうものか簡単に見ていく。
world database
worldデータベースは国と都市に関するデータで、テーブルがたった3つしかないミニマルなデータセットである。
題材のわかりやすさに加え、多対多のリレーションシップが含まれておらず、スキーマがシンプルである。DB自体の勉強というよりも、サンプルアプリケーション等でとりあえず使うといった用途に向いている気がする。
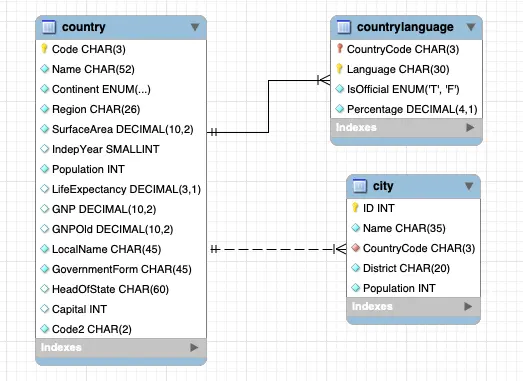
下記は統計情報を保存しているテーブル mysql.innodb_table_stats からの抜粋であるが、最大の city テーブルで4000行程度とテーブルサイズも小さい。
| table_name | n_rows | clustered_index_size | sum_of_other_index_sizes |
|-----------------|--------|----------------------|--------------------------|
| city | 4150 | 25 | 5 |
| countrylanguage | 984 | 5 | 4 |
| country | 239 | 6 | 0 |employees database
employeesデータベースは従業員に関するデータであり、部署・給与・役職などを含む計6テーブルで構成される。
worldデータベース同様、リレーションシップは単純であるが、1対多、多対多の両方が含まれることに加え、salaries や titles といった時系列のデータが含まれる特徴がある。
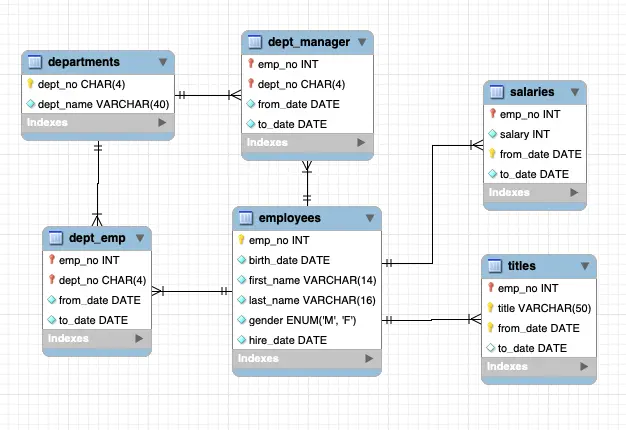
またsalariesテーブルが280万行程あり、他にも数十万行のテーブルが存在するため、大きめのデータベースとなっている。これくらいのサイズであればパフォーマンスの試験にも使える可能性があり、汎用性が高そうだ。
| table_name | n_rows | clustered_index_size | sum_of_other_index_sizes |
|--------------|---------|----------------------|--------------------------|
| salaries | 2838426 | 7016 | 0 |
| titles | 442129 | 1380 | 0 |
| dept_emp | 331143 | 865 | 353 |
| employees | 299468 | 1057 | 0 |
| dept_manager | 24 | 1 | 1 |
| departments | 9 | 1 | 1 |sakila database
sakilaデータベースは蔦屋のようなレンタルDVDショップを想定したデータベースであり、全16テーブルで構成されている。
これまでのデータベースに比べると明らかに複雑なスキーマになっており、1つのシステムをきちんと想定して作られた、という立ち位置かなと思う。

テーブルサイズはemployee程ではない。
| table_name | n_rows | clustered_index_size | sum_of_other_index_sizes |
|---------------|--------|----------------------|--------------------------|
| payment | 16125 | 97 | 35 |
| rental | 16074 | 97 | 60 |
| film_actor | 5462 | 11 | 5 |
| inventory | 4581 | 10 | 9 |
| film | 1000 | 11 | 5 |
| film_category | 1000 | 3 | 1 |
| film_text | 1000 | 11 | 1 |
| address | 603 | 6 | 1 |
| city | 600 | 3 | 1 |
| customer | 599 | 5 | 3 |
| actor | 200 | 1 | 1 |
| country | 109 | 1 | 0 |
| category | 16 | 1 | 0 |
| language | 6 | 1 | 0 |
| staff | 2 | 4 | 2 |
| store | 2 | 1 | 2 |スキーマを見ていくことで論理設計の参考になりそうなのと、ショップ側の視点で film / inventory / staff / store を操作するシステムを作ったり、逆に顧客側の視点で customer / rental を操作するシステムを作ることができそうだ。 軽く見た感じではインデックスもFKに関するものしかないようなので、1つの業務システムを作る題材として使えそうだ。
さいごに
特に事前情報は無しで3つのデータベースをピックアップしてみたが、それぞれ特色が異なって面白かった。今後何か手元で試すときに使いたい。
また、億超えのテーブルを使ったパフォーマンス試験や、Geometry型を使った実験などでは今回のデータは使えないので、折を見てデータベースを足していけたらと思っている。